< RESOURCES / >
The Strategic Data Engineer: A Fintech Leader's Guide

In fintech, a data engineer is the architect of your entire data ecosystem. They design, build, and maintain the processing systems that handle the constant flow of financial data. Their primary role is to ensure that data is reliable, secure, and accessible for everyone from business analysts to AI algorithms.
Put simply, their work is the foundation for everything you want to achieve, directly impacting revenue, risk, and time-to-market.
Why a Data Engineer is the Architect of Fintech
Think of a modern city. Before you can build skyscrapers or manage traffic, someone must design and lay the critical infrastructure—the power grid, water mains, and road network. Without this foundation, the city cannot function, let alone grow.
A data engineer plays that exact role inside a fintech company.
They don't just write code; they are strategic planners designing the data "power grid." This infrastructure enables every other part of the business, from real-time fraud detection algorithms that protect revenue to the analytics platforms that guide executive decisions.
The Foundation for Business Innovation
Every forward-thinking fintech initiative—whether AI-driven personalization, predictive risk modeling, or automated compliance reporting—starts with clean, accessible, and reliable data. The data engineer makes this possible.
They build the data pipelines that ingest raw transaction data, cleanse it, and structure it for analysis.
This foundational work has a direct impact on business outcomes:
- Faster Time-to-Market: Well-designed data systems allow product teams to build and launch new features faster, as they aren’t delayed by poor data access or quality.
- Reduced Operational Costs: By automating data flows and optimizing storage, engineers reduce manual effort and cut expensive computational waste.
- Mitigated Compliance Risk: They build systems that guarantee data lineage and quality—essential for meeting strict financial regulations like PSD2 and Open Banking.
A fintech company without a skilled data engineer is like a bank operating without a vault. Its core asset—data—is vulnerable, disorganized, and ultimately unusable for creating value or ensuring security.
Navigating the Competitive Hiring Landscape
The strategic importance of this role has created an intense battle for talent. In Hungary, particularly in the Budapest tech scene, demand for skilled data engineers has skyrocketed.
While the median time to hire is around 34 days, a significant portion—nearly 30-40%—of these roles are filled in just 10 days. This pace highlights the urgency with which companies like EPAM Systems and Deutsche Telekom IT Solutions HU seek this expertise. You can discover more insights about the Hungarian data engineering market to understand why finding top talent is a major challenge.
This competitive environment makes it clear: hiring a good data engineer isn't just a recruitment task; it's a strategic business move. The right person doesn't just manage data; they build the architecture that enables you to scale, remain secure, and maintain a competitive edge.
Understanding this role is the first step toward building a resilient, data-driven organization. Your ability to innovate is directly tied to the quality of the data infrastructure your team builds. From here, the conversation shifts from why you need a data engineer to how you find one with the right skills to drive your business forward.
Ready to build a data foundation that accelerates your fintech roadmap?
Book a consultation with our data engineering experts today.
The Modern Fintech Data Engineering Skillset
To build the kind of data infrastructure fintech relies on, a modern data engineer needs more than just a passing familiarity with a few databases. Their skillset is a specific mix of deep foundational knowledge, hands-on expertise with sophisticated pipeline tools, and fluency in at least one major cloud environment. This isn't about collecting certifications; it's about mastering the right tools to solve specific, high-stakes business problems.
A skilled data engineer has a direct, measurable impact on the business. Their ability to design efficient data systems slashes operational costs. Their command of real-time tools helps mitigate fraud risk. The architectural choices they make can shorten the launch time for new, data-driven financial products by months.
Foundational Technical Skills
Before a data engineer can build complex data pipelines, they need an unshakeable command of the fundamentals. These are the non-negotiables upon which all other data work rests. Without this solid foundation, any data architecture is inefficient, insecure, and difficult to maintain.
These core skills include:
- Advanced SQL: This goes beyond simple
SELECT * FROMqueries. A fintech data engineer must write complex, highly optimized queries to untangle intricate financial datasets. This is crucial for regulatory reporting and for powering BI dashboards used by the C-suite. - Python Proficiency: Python is the de facto language of data. Engineers use it to script ETL jobs, automate workflows, and integrate various components of the data stack, which boosts team efficiency and reduces costly manual errors.
- Data Modeling and Warehousing: Designing logical and physical data models is essential. A well-designed schema in a data warehouse like Snowflake or BigQuery ensures data is not just stored cost-effectively but is also structured for fast, reliable analytics when the business needs answers.
Core Pipeline and ETL Technologies
Once the foundation is solid, the next layer of expertise involves the tools that move, transform, and process data at scale. In fintech, where data velocity and volume are immense, this is what separates a functional data platform from a high-performance one.
The key tools here are Apache Spark for large-scale batch processing and Apache Kafka for handling real-time data streams. Kafka, in particular, is critical for use cases like instant fraud detection and live transaction monitoring.
The ability to manage high-throughput, low-latency data streams allows a fintech platform to process millions of events per second—a core requirement for reducing financial risk and providing a seamless customer experience.
Cloud Platform Expertise
Modern data engineering is overwhelmingly cloud-native. A senior data engineer must be adept at building and managing infrastructure on at least one of the three major cloud platforms—AWS, Google Cloud (GCP), or Azure. This goes beyond launching virtual machines; it requires a deep understanding of the ecosystem of data services each provider offers.
A data engineer's cloud expertise translates directly into business agility. Knowing when to use the right managed service—like AWS Glue for ETL or GCP's Pub/Sub for messaging—can shorten development timelines by months and significantly lower the total cost of ownership.
This expertise breaks down into a few key areas:
- Managed Data Services: Knowing when to use services like Amazon RDS, Google Cloud Storage, or Azure Data Factory to deliver solutions faster and more reliably.
- Infrastructure as Code (IaC): Using tools like Terraform to automate the deployment of data infrastructure. This ensures consistency and dramatically reduces the risk of human error.
- Security and Governance: Implementing cloud security best practices to protect sensitive financial data and ensure compliance with regulatory requirements.
As the financial world intersects with decentralized technologies, a new skillset is emerging. For today's fintech data engineers, mastering blockchain data analysis to extract insights from on-chain transactions and dApps provides a critical advantage. This is no longer a niche skill; it helps companies explore new product frontiers and anticipate emerging risks.
Building Scalable Data Architectures for Finance
Choosing the right data architecture is one of the most significant decisions a fintech leader will make. This is not just a technical debate; it's a strategic choice that dictates how quickly you can ship products, how effectively you manage risk, and how well you serve your customers. A top-tier data engineer doesn't just connect pipes—they design the blueprint that will either fuel your growth or become a bottleneck.
The architectural choices you make today will define the limits of your ambition tomorrow.
Data Lakes Versus Data Warehouses
Two common terms are the data lake and the data warehouse. They are not interchangeable, and understanding the difference is crucial.
- A data lake is a vast repository of raw information. It stores large amounts of unstructured and semi-structured data in its native format—transaction logs, customer support chats, market data streams. Its value lies in flexibility and low-cost storage, making it ideal for data scientists training machine learning models for fraud detection or credit scoring.
- A data warehouse, in contrast, is a highly organized repository. Data is cleaned, structured, and cataloged before it is stored. This makes it incredibly fast and efficient for business intelligence (BI) and reporting. When your finance team needs a quarterly compliance report, they pull it from the clean, reliable data in a warehouse.
The Best of Both Worlds: The Data Lakehouse
For years, the choice felt binary: the flexibility of a lake or the structure of a warehouse, often forcing companies to maintain two separate, expensive systems. The modern solution is the data lakehouse, a hybrid architecture that combines the strengths of both.
A data lakehouse provides the low-cost, scalable storage of a data lake for all your raw data, with the reliability, performance, and governance of a data warehouse layered on top. This unified approach reduces complexity and cost.
For a fintech, this means a single system can power both the machine learning teams building predictive models and the analytics teams creating executive dashboards. It breaks down data silos, establishes a single source of truth, and shortens the path from idea to market.
This diagram shows how a data engineer’s skills bridge the gap between foundational coding, complex pipeline construction, and the cloud environments needed to bring these modern architectures to life.
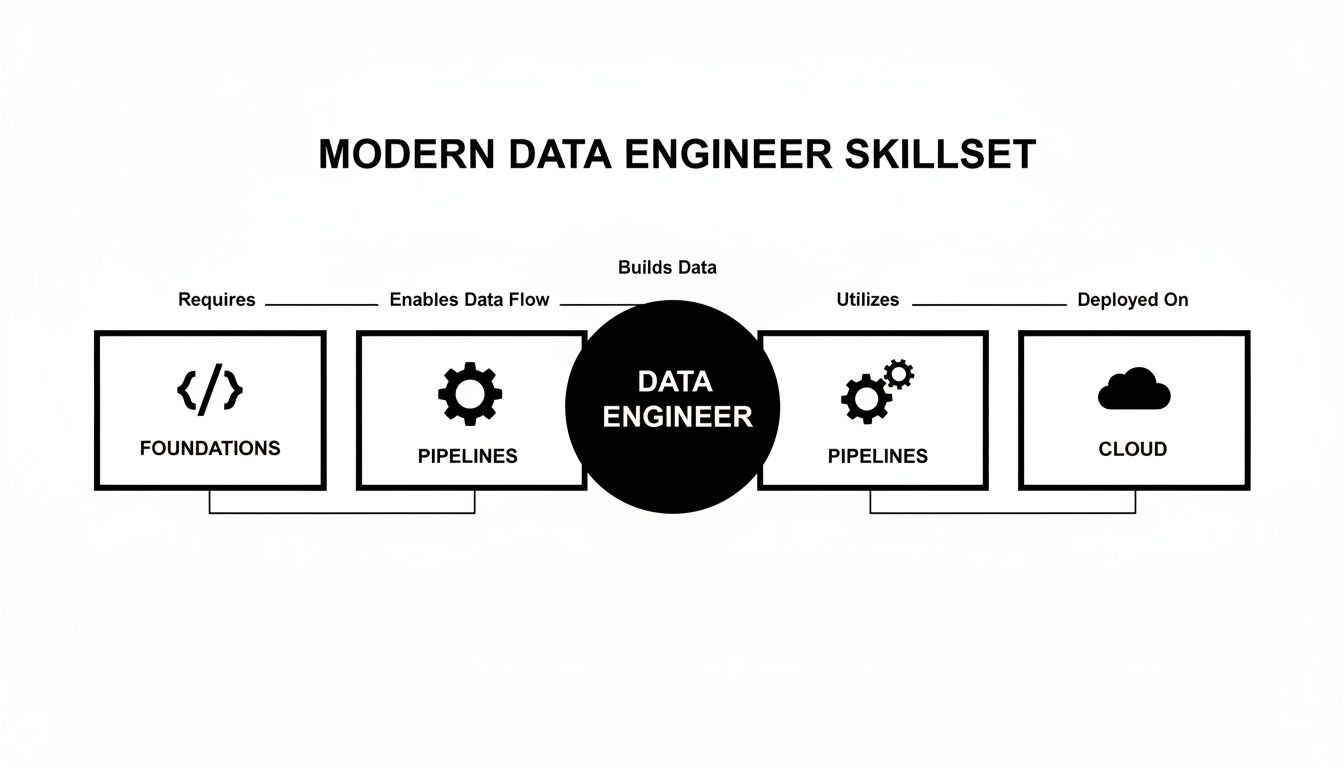
As you can see, you cannot build robust pipelines or manage cloud services without a rock-solid foundation in coding and core data principles.
A Sample Fintech Data Pipeline
To illustrate, let's walk through a simple data pipeline for processing customer card transactions. A data engineer would build a system to handle these key stages:
- Ingestion: Transaction data arrives from payment processors in real-time. A tool like Apache Kafka captures these events reliably, ensuring no transaction is dropped.
- Transformation: The raw data is messy. It needs to be cleaned, validated, and enriched with other information, like customer details from a CRM. This "ETL" (Extract, Transform, Load) work is often done using a processing engine like Apache Spark. For a deeper look at managing these workflows, check out our guide on integrating Databricks with Airflow for powerful pipeline management.
- Storage: The cleaned data is stored in a structured format within a data lakehouse, ready for use.
- Serving: The data is now put to work. An analyst can query it with SQL to build a dashboard in Tableau, while a machine learning model accesses it to refine its fraud detection algorithm.
Each stage is a potential point of failure. A network issue during ingestion or a formatting error during transformation can corrupt the entire flow, leading to poor business decisions. A great data engineer anticipates these risks, building in monitoring, alerting, and automated recovery systems to make the pipeline resilient and the data trustworthy. That reliability is the bedrock of compliance and customer trust.
Mastering Security and Compliance in Financial Data

In fintech, security isn't just a feature; it's the foundation of your business. A misstep can create an existential threat. This is where a skilled data engineer becomes your most crucial line of defense, building systems that are secure by design, not as an afterthought.
Their work is what separates a resilient, compliant platform from one that’s a ticking time bomb of fines and reputational damage. A single data leak can cost millions; the average breach in the financial industry hit $5.9 million in 2023. For a data engineer in this space, security is the job.
They don't just add security measures at the end. They weave them into the fabric of the data architecture, turning compliance from a reactive, box-ticking exercise into a proactive, automated discipline. This approach drastically reduces human error and satisfies regulators.
Core Pillars of Fintech Data Security
To safeguard sensitive financial data, a data engineer relies on a few non-negotiable security practices. These are directly tied to protecting revenue, unlocking new markets, and building customer trust.
Here are the essentials:
- End-to-End Encryption: Data must be protected everywhere. This means strong encryption for data at rest (in a database or data lake) and in transit (moving between services or over a network). This is the baseline for preventing unauthorized access.
- Robust Access Control: Not everyone in your company needs to see sensitive customer data. Data engineers implement strict, role-based access control (RBAC) and follow the principle of least privilege. This means people and systems can only access the specific data they need to do their jobs, shrinking the internal attack surface.
- Data Anonymization and Masking: For analytics, development, or testing, you cannot use live customer data. Techniques like tokenization or pseudonymization are used. Engineers replace sensitive details (like names or account numbers) with irreversible tokens, allowing teams to work with realistic data without exposing personal information.
A proactive 'security-by-design' mindset is the only sustainable approach in fintech. Bolting on security after the fact is more expensive, less effective, and signals to regulators that security is an afterthought.
Navigating PSD2 and Open Banking Compliance
Regulations like PSD2 and Open Banking are mandates for secure, consent-driven data sharing. A data engineer builds the technical infrastructure to make this happen safely.
They architect secure APIs, manage consent logs, and implement the strong customer authentication (SCA) these frameworks demand. Getting this right allows the business to innovate with new open banking services while ensuring every data-sharing interaction is compliant and auditable, thereby avoiding significant non-compliance penalties.
A comprehensive cloud security compliance guide can be an invaluable resource for navigating these requirements.
The Security-by-Design Checklist for a Data Engineer
Building a secure data platform requires a methodical approach. This checklist helps ensure security is integrated from day one:
- Classify All Data: As soon as data enters your system, identify and tag it based on sensitivity (e.g., PII, financial records).
- Automate Security Scans: Integrate automated security testing into your CI/CD pipelines to catch vulnerabilities before they reach production. Regular checks, like penetration testing as a service, are essential.
- Implement Immutable Logging: Ensure all data access and modifications are logged in a tamper-proof system, providing a clear audit trail for compliance and incident investigation.
- Enforce Secure Defaults: Configure every data system and service with its most secure settings out of the box, forcing a conscious decision to relax any control.
- Conduct Regular Audits: Routinely review access logs, permissions, and security configurations to ensure they remain appropriate and compliant.
By adhering to these principles, a data engineer does far more than just move data; they become a guardian of the company’s most critical asset.
Ready to build a data infrastructure that meets the highest standards of security and compliance?
Request a proposal and let our experts secure your data foundation.
How to Hire and Scale Your Data Engineering Team
Building a data engineering function is a high-leverage investment for any fintech, but finding the right people is a serious bottleneck. The market is highly competitive, and your success depends on a strategy that goes beyond matching keywords on a resume. You need problem-solvers, not just candidates who can list technologies.
An effective hiring process focuses on a candidate's ability to think architecturally and solve business problems. Resumes are just the starting point. The real test is how they think, as this reveals engineers who connect technical decisions to outcomes like cutting operational costs or shipping products faster.
Designing a Robust Interview Process
To find top-tier talent, your interview process should reflect real-world challenges. A well-designed process will assess how a data engineer thinks, builds, and collaborates.
Your interviews should focus on these key areas:
- System Design: Present a fintech-specific scenario, like designing a real-time fraud detection pipeline. The goal is not to find a "right" answer but to see how they handle trade-offs, choose tools, and defend their architectural decisions.
- Data Modeling: Provide a complex business requirement, such as structuring data to analyze risk for a new lending product. Ask them to design a schema and justify their choices, especially around normalization and scalability.
- Advanced SQL and Python Challenges: Move beyond basics. Pose an analytical question that requires sophisticated window functions, common table expressions (CTEs), and complex data manipulation in Python.
A strong take-home task is invaluable. Ask candidates to build a small-scale ETL pipeline using a sample financial dataset. You're evaluating code quality, test coverage, and documentation—the hallmarks of a professional who respects their craft.
Understanding the Competitive Compensation Landscape
You can't hire effectively without understanding market rates. In Hungary, salaries for data engineers are competitive. PayScale data shows an average base salary of around 700,000 HUF per month (8.4 million HUF annually), with the most experienced engineers earning up to 16 million HUF.
Factors that command higher salaries include advanced degrees, management experience, and mastery of in-demand stacks like Databricks, Snowflake, and Terraform. With a national pool of over 80,000 developers, data engineering remains one of the best-paid tech roles in Hungary. You can explore the Hungarian data engineering salary landscape on Built In for more details.
Strategic Team Augmentation
Direct hiring is slow and risky. When you need speed and certainty, strategic team augmentation is a powerful alternative. Instead of spending months on a recruitment cycle, you can embed pre-vetted, senior data engineers directly into your team.
This approach bypasses hiring friction and provides immediate access to the expertise needed to advance critical projects. For a closer look, see how strategic team augmentation can help you scale effectively. It’s a proven way to de-risk delivery and meet your roadmap goals on time.
Ready to bypass the hiring grind and accelerate your data initiatives?
Book a call to discuss your data engineering needs today.
FAQ
What are the key differences between a junior and a senior data engineer?
A junior engineer executes well-defined tasks within an existing pipeline. A senior data engineer, however, owns the entire data lifecycle. They design scalable architectures, anticipate business needs, mentor the team, and make strategic decisions that balance cost, performance, and security.
How long should it take to hire a data engineer?
The market average is around 30-40 days, but this can be optimistic. A specialized role in a competitive hub like Budapest can take much longer. Working with a partner can shrink that timeline to just a few weeks by providing access to a network of pre-vetted talent.
Is it better to hire a generalist or a specialist?
For an early-stage fintech, a generalist who can work across the entire data stack is often more valuable. As your data platform matures and scales, you will need specialists with deep expertise in areas like data streaming (Kafka) or warehousing (Snowflake) to optimize performance and control costs.
Ready to Move Faster?
Building a solid data foundation is the engine of your business. We've shown how a skilled data engineer architects real fintech innovation—enabling you to launch products faster, navigate compliance, and drive revenue. But knowing you need one and executing a data strategy are two different things. The path is filled with challenges, from a difficult hiring market to architectural missteps that can cause months of delays.
This is where the right partner makes a difference. Going it alone is slow, expensive, and risky. You need senior talent that understands the unique security demands of finance, can integrate seamlessly with your team, and delivers value from day one.
From Idea to Impact
That's where SCALER comes in. We provide more than just top-tier data engineers; we offer the hands-on consulting to help you avoid common pitfalls and get to market faster. We help you move from a concept to a live, secure, and scalable data platform.
Hungary’s tech scene is a key part of our strategy. With around 70 institutions producing 2,700 ICT graduates and 12,000 STEM students annually, the country has a deep talent pool. This feeds a community of over 80,000 software developers. You can learn more about the Hungarian developer market and its advantages on alcor-bpo.com. SCALER taps into this ecosystem to find the elite engineers your projects demand.
Your ability to innovate is directly tied to the strength of your data infrastructure. A partnership with SCALER removes the hiring delays, skill gaps, and project risks that stand between you and your business goals.
We help you build the data foundation that powers:
- Real Innovation: Give your product and analytics teams the clean, reliable data they need.
- Lower Risk: Ensure your architecture meets tough standards like PSD2.
- Smarter Spending: Design lean, efficient pipelines that scale without breaking your budget.
Stop letting hiring friction and execution risk dictate your roadmap. Let's build the data infrastructure that will define your future.
Book a call to talk about your data engineering needs and get your project moving.
FAQ
ETL vs. ELT: What’s the real difference for a fintech?
It comes down to when you transform your data.
- ETL (Extract, Transform, Load) is the traditional approach. You extract data, transform it into a clean, structured format, and then load it into your data warehouse. This is ideal for compliance reporting and BI, ensuring analysts work with pre-vetted data.
- ELT (Extract, Load, Transform) is the modern approach. You extract raw data and load it directly into a data lake or lakehouse. The transformation happens only when the data is needed for a specific purpose. This offers flexibility and speed, which is critical for machine learning and R&D.
How does a data engineer help with AI and machine learning?
A data engineer builds the reliable, high-speed data pipelines that feed machine learning models. A data scientist builds and trains the models, but they are dependent on the data engineer to provide clean, well-structured data.
This work includes:
- Feature Engineering: Taking raw data and creating the specific, clean "features" a model needs to learn from.
- Data Accessibility: Designing systems that allow data scientists to quickly pull large datasets for experiments.
- MLOps: Setting up the production infrastructure to serve models to users, monitor their performance, and manage data versions.
If your data scientists are spending most of their time cleaning data, you have a data engineering problem, not a data science problem.
We’re a startup. What’s the first step in building a data team?
Start small and solve one high-value problem first.
- Pick One Business Goal: Focus on a clear target, like "reduce customer churn by 10%" or "block more fraudulent transactions."
- Hire Your First Data Engineer: Bring on a versatile, hands-on data engineer who can build the initial infrastructure to collect and process the data needed for that one goal.
- Keep the Tech Stack Simple: Use a lean, cloud-based toolset like GCP’s BigQuery or AWS Redshift to get started quickly without a large upfront investment.
This approach delivers a measurable win quickly, making it easier to justify further investment.
How can we measure the ROI of a data engineer?
You measure their value in business outcomes, not lines of code.
The ROI of a data engineer isn't found in the complexity of their pipelines; it's measured by the business opportunities their work unlocks—from slashing fraud losses to launching products months ahead of the competition.
Track these business metrics to see the return:
- Cost Savings: How much was saved by automating manual reporting or optimizing cloud storage?
- New Revenue: Can you attribute revenue to a new feature (like a recommendation engine) enabled by the data infrastructure?
- Risk Reduction: What is the financial value of compliance fines avoided or fraudulent transactions blocked?
- Team Productivity: How many hours are your analytics and product teams saving now that they have fast, reliable access to trustworthy data?
Your data infrastructure is the foundation of your competitive edge. A partnership with SCALER removes the delays and risks that stand between you and your business goals.
< MORE RESOURCES / >

Fintech
A Guide to Epic Store Szeged and the Local Tech Scene

Fintech
A Guide to Designing a Nordic Light Office for Technical Teams

Fintech
A Tech Employer's Guide to Hungary's Social Security System

Fintech
How to Choose an IT Company That Drives Business Outcomes

Fintech
A Consultant's Guide to Part-Time Jobs in Budapest

Fintech
A Consultant's Guide to Peppol Integration for E-Invoicing

Fintech
A Tech Leader's Guide to Nearshore Development

Fintech
PSD2 Integration for CTOs: Real-World Challenges and Architecture Insights

Team augmentation
Hiring vs. Outsourcing: Finding the Right Balance with Team Augmentation

Fintech